Chapitre 1 Présentation
Certaines parties de ce chapitre sont extraites du cours de Julien Barnier “Introduction à R et au tidyverse” (https://juba.github.io/tidyverse)
1.1 Introduction
1.1.1 À propos de R
R est un langage orienté vers le traitement et l’analyse quantitative des données, dérivé du langage. Il est développé depuis les années 90 par un groupe de volontaires de différents pays et par une grande communauté d’utilisateurs. C’est un logiciel libre, publié sous licence GNU GPL.
Utilisation de R présente plusieurs avantages:
- c’est un logiciel multiplateforme, qui fonctionne aussi bien sur des systèmes Linux, Mac OS X ou Windows.
- c’est un logiciel libre, développé par ses utilisateurs, diffusable et modifiable par tout un chacun.
- c’est un logiciel gratuit.
- c’est un logiciel très puissant, dont les fonctionnalités de base peuvent être étendues à l’aide d’extensions développées par la communauté. Il en existe plusieurs milliers.
- c’est un logiciel dont le développement est très actif et dont la communauté d’utilisateurs et l’utilisation ne cessent de grandir.
- c’est un logiciel avec des capacités graphiques intéressantes.
Comme rien n’est parfait, on peut également trouver quelques inconvénients :
- le logiciel, la documentation de référence et les principales ressources sont en anglais. Il est cependant parfaitement possible d’utiliser R sans spécialement maîtriser cette langue et il existe de plus en plus de ressources francophones.
- R n’est pas un logiciel au sens classique du terme, mais plutôt un langage de programmation. Il fonctionne à l’aide de scripts (des petits programmes) édités et exécutés au fur et à mesure de l’analyse.
- en tant que langage de programmation, R à la réputation d’être difficile d’accès, notamment pour ceux qui n’ont jamais été programmés auparavant.
Au départ cantonné à la sphère universitaire, R est aujourd’hui de plus en plus utilisé dans des grandes entreprises et administrations, car il coûte beaucoup moins cher que ses concurrents (par exemple SAS) tout en étant très peformant.
Ce document ne demande aucun prérequis en informatique ou en programmation. Juste un peu de motivation pour l’apprentissage du langage et, si possible, des données intéressantes sur l’application appliquée les connaissances acquiert.
L’aspect langage de programmation et la difficulté qui en découle peut sembler des inconvénients importants. Le fait de structurer ses analyses sous forme de scripts (suite d’instructions effectuant les différentes opérations d’une analyse) présente cependant de nombreux avantages :
- le script garde par ordre chronologique l’ensemble des étapes d’une analyse, des données des données à leur analyser en passant par les manipulations et les recodages.
- on peut à tout moment revenir en arrière et modifier ce qui a été fait.
- il est très rapide de réexécuter une suite d’opérations complexes.
- on peut très facilement mettre à jour les résultats en cas de modification des sources de données.
- le script garanti, sous certaines conditions, la reproductibilité des résultats obtenus.
1.1.2 À propos de RStudio
RStudio n’est pas à proprement parler une interface graphique pour R, il s’agit plutôt d’un environnement de développement intégré, qui propose des outils et facilite l’écriture de scripts et l’usage de R au quotidien. C’est une interface bien supérieure à celles fournies par défaut fournies installe R sous Windows ou sous Mac ^ [Sous Linux R n’est fourni que comme un outil en ligne de commande.].
Pour paraphraser Hadrien Commenges, il n’y a pas d’obligation à utiliser RStudio, mais il y a une obligation à ne pas utiliser les interfaces de R par défaut.
RStudio est également un logiciel libre et gratuit. Une version payante existe, mais elle ne propose pas de fonctionnalités indispensables.
1.1.3 À propos du tidyverse
Le tidyverse est un ensemble d’extensions pour R (code développé par la communauté permettant de rajouter des fonctionnalités à R) construites autour d’une philosophie commune et exercé pour fonctionner ensemble. Elles facilitent l’utilisation de R dans les domaines les plus courants : manipulation des données, recodages, production de graphiques, etc.
1.1.4 Structure du document
Ce document est composé de deux grandes fêtes :
- Une Introduction à R , qui présente les bases du langage R et de l’interface RStudio
- Une Introduction au tidyverse qui présente cet ensemble d’extensions pour la visualisation, la manipulation des données et l’export de résultats
1.1.5 Prérequis
Le seul prérequis pour suivre ce document est installé R et RStudio sur votre ordinateur. Il s’agit de deux logiciels libres, gratuits, téléchargeables en ligne et fonctionnant sous PC, Mac et Linux.
Pour l’installateur R, il suffit de se rendre sur une des pages suivantes :
Pour l’installateur RStudio, rendez-vous sur la page suivante et téléchargez la version adaptée à votre système https://www.rstudio.com/products/rstudio/download/#download
1.2 Prise en main
Une fois R et RStudio installés sur votre machine, nous n’allons pas lancer R mais plutôt RStudio.
RStudio n’est pas à proprement parler une interface graphique qui permettrait d’utiliser R de manière “classique” via la souris, des menus et des boîtes de dialogue. Il s’agit plutôt de ce qu’on appelle un Environnement de développement intégré (IDE) qui facilite l’utilisation de R et le développement de scripts.
1.2.1 La console
1.2.1.1 L’invite de commandes
Au premier lancement de RStudio, l’écran principal est découpé en trois grandes zones :
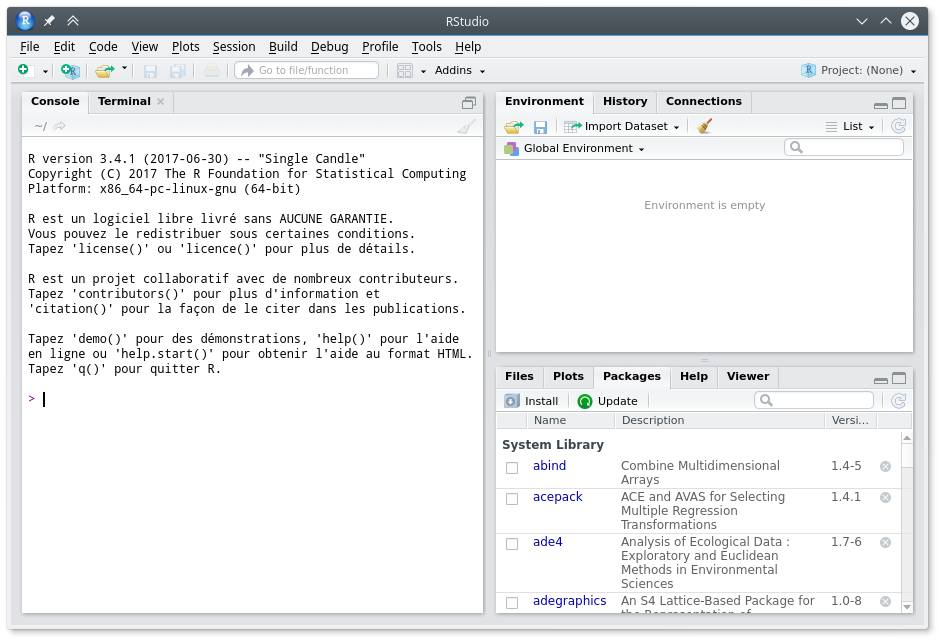
Interface de Rstudio
La zone de gauche se nomme Console. À son démarrage, RStudio a lancé une nouvelle session de R et c’est dans cette fenêtre que nous allons pouvoir interagir avec lui.
La Console doit normalement afficher un texte de bienvenue ressemblant à ceci :
R version 3.5.2 (2018-12-20) -- "Eggshell Igloo"
Copyright (C) 2018 The R Foundation for Statistical Computing
Platform: x86_64-pc-linux-gnu (64-bit)
R est un logiciel libre livré sans AUCUNE GARANTIE.
Vous pouvez le redistribuer sous certaines conditions.
Tapez 'license()' ou 'licence()' pour plus de détails.
R est un projet collaboratif avec de nombreux contributeurs.
Tapez 'contributors()' pour plus d'information et
'citation()' pour la façon de le citer dans les publications.
Tapez 'demo()' pour des démonstrations, 'help()' pour l'aide
en ligne ou 'help.start()' pour obtenir l'aide au format HTML.
Tapez 'q()' pour quitter R.suivi d’une ligne commençant par le caractère > et sur laquelle devrait se trouver votre curseur. Cette ligne est appelée l’invite de commande (ou prompt en anglais). Elle signifie que R est disponible et en attente de votre prochaine commande.
Nous pouvons tout de suite lui fournir une première commande, en saisissant le texte suivant puis en appuyant sur Entrée :
2 + 2## [1] 4R nous répond immédiatement, et nous pouvons constater avec soulagement qu’il sait faire des additions à un chiffre1. On peut donc continuer avec d’autres opérations :
5 - 7## [1] -24 * 12## [1] 48-10 / 3## [1] -3.3333335^2## [1] 25Cette dernière opération utilise le symbole ^ qui représente l’opération puissance. 5^2 signifie donc “5 au carré”, soit 25.
1.2.1.2 Précisions concernant la saisie des commandes
Lorsqu’on saisit une commande, les espaces autour des opérateurs n’ont pas d’importance. Les trois commandes suivantes sont donc équivalentes, mais on privilégie en général la deuxième pour des raisons de lisibilité du code.
10+2
10 + 2
10 + 2Quand vous êtes dans la console, vous pouvez utiliser les flèches vers le haut et vers le bas pour naviguer dans l’historique des commandes que vous avez tapées précédemment. Vous pouvez à tout moment modifier la commande affichée, et l’exécuter en appuyant sur Entrée.
Enfin, il peut arriver qu’on saisisse une commande de manière incomplète : oubli d’une parenthèse, faute de frappe, etc. Dans ce cas, R remplace l’invite de commande habituel par un signe + :
4 *
+Cela signifie qu’il “attend la suite”. On peut alors soit compléter la commande sur cette nouvelle ligne et appuyer sur Entrée, soit, si on est perdu, tout annuler et revenir à l’invite de commandes normal en appuyant sur Esc ou Échap.
1.2.2 Objets
1.2.2.1 Objets simples
Faire des calculs c’est bien, mais il serait intéressant de pouvoir stocker un résultat quelque part pour pouvoir le réutiliser ultérieurement sans avoir à faire du copier/coller.
Pour conserver le résultat d’une opération, on peut le stocker dans un objet à l’aide de l’opérateur d’assignation <-. Cette “flèche” stocke ce qu’il y a à sa droite dans un objet dont le nom est indiqué à sa gauche.
Prenons tout de suite un exemple :
x <- 2Cette commande peut se lire “prend la valeur 2 et mets la dans un objet qui s’appelle x”.
Si on exécute une commande comportant juste le nom d’un objet, R affiche son contenu :
x## [1] 2On voit donc que notre objet x contient bien la valeur 2.
On peut évidemment réutiliser cet objet dans d’autres opérations. R le remplacera alors par sa valeur :
x + 4## [1] 6On peut créer autant d’objets qu’on le souhaite.
x <- 2
y <- 5
resultat <- x + y
resultat## [1] 7Attention
Les noms d’objets peuvent contenir des lettres, des chiffres, les symboles . et _. Ils ne peuvent pas commencer par un chiffre. Attention, R fait la différence entre minuscules et majuscules dans les noms d’objets, ce qui signifie que x et X seront deux objets différents, tout comme resultat et Resultat.
De manière générale, il est préférable d’éviter les majuscules (pour les risques d’erreur) et les caractères accentués (pour des questions d’encodage) dans les noms d’objets.
De même, il faut essayer de trouver un équilibre entre clarté du nom (comprendre à quoi sert l’objet, ce qu’il contient) et sa longueur. Par exemple, on préfèrera comme nom d’objet taille_conj1 à taille_du_conjoint_numero_1 (trop long) ou à t1 (pas assez explicite).
Quand on assigne une nouvelle valeur à un objet déjà existant, la valeur précédente est perdue. Les objets n’ont pas de mémoire.
x <- 2
x <- 5
x## [1] 5De la même manière, assigner un objet à un autre ne crée pas de “lien” entre les deux. Cela copie juste la valeur de l’objet de droite dans celui de gauche :
x <- 1
y <- 3
x <- y
x## [1] 3### Si on modifie y, cela ne modifie pas x
y <- 4
x## [1] 3On le verra, les objets peuvent contenir tout un tas d’informations. Jusqu’ici on n’a stocké que des nombres, mais ils peuvent aussi contenir des chaînes de caractères (du texte), qu’on délimite avec des guillemets simples ou doubles (' ou ") :
chien <- "Chihuahua"
chien## [1] "Chihuahua"1.2.2.2 Vecteurs
Imaginons maintenant qu’on a demandé la taille en centimètres de 5 personnes et qu’on souhaite calculer leur taille moyenne. On pourrait créer autant d’objets que de tailles et faire l’opération mathématique qui va bien :
taille1 <- 156
taille2 <- 164
taille3 <- 197
taille4 <- 147
taille5 <- 173
(taille1 + taille2 + taille3 + taille4 + taille5) / 5## [1] 167.4Cette manière de faire n’est évidemment pas pratique du tout. On va plutôt stocker l’ensemble de nos tailles dans un seul objet, de type vecteur, avec la fonction combine appeler avec le raccourci c :
tailles <- c(156, 164, 197, 147, 173)Si on affiche le contenu de cet objet, on voit qu’il contient bien l’ensemble des tailles saisies :
tailles## [1] 156 164 197 147 173Un vecteur dans R est un objet qui peut contenir plusieurs informations du même type, potentiellement en très grand nombre.
L’avantage d’un vecteur est que lorsqu’on lui applique une opération, celle-ci s’applique à toutes les valeurs qu’il contient. Ainsi, si on veut la taille en mètres plutôt qu’en centimètres, on peut faire :
tailles_m <- tailles / 100
tailles_m## [1] 1.56 1.64 1.97 1.47 1.73Cela fonctionne pour toutes les opérations de base :
tailles + 10## [1] 166 174 207 157 183tailles^2## [1] 24336 26896 38809 21609 29929Imaginons maintenant qu’on a aussi demandé aux cinq mêmes personnes leur poids en kilos. On peut alors créer un deuxième vecteur :
poids <- c(45, 59, 110, 44, 88)On peut alors effectuer des calculs utilisant nos deux vecteurs tailles et poids. On peut par exemple calculer l’indice de masse corporelle (IMC) de chacun de nos enquêtés en divisant leur poids en kilo par leur taille en mètre au carré :
imc <- poids / (tailles / 100) ^ 2
imc## [1] 18.49112 21.93635 28.34394 20.36189 29.40292Un vecteur peut contenir des nombres, mais il peut aussi contenir du texte. Imaginons qu’on a demandé aux 5 mêmes personnes leur niveau de diplôme : on peut regrouper l’information dans un vecteur de chaînes de caractères. Une chaîne de caractère contient du texte libre, délimité par des guillemets simples ou doubles :
diplome <- c("CAP", "Bac", "Bac+2", "CAP", "Bac+3")
diplome## [1] "CAP" "Bac" "Bac+2" "CAP" "Bac+3"L’opérateur :, lui, permet de générer rapidement un vecteur comprenant tous les nombres entre deux valeurs, opération assez courante sous R :
x <- 1:10
x## [1] 1 2 3 4 5 6 7 8 9 10Enfin, notons qu’on peut accéder à un élément particulier d’un vecteur en faisant suivre le nom du vecteur de crochets contenant le numéro de l’élément désiré. Par exemple :
diplome[2]## [1] "Bac"Cette opération, qui utilise l’opérateur [], permet donc la sélection d’éléments d’un vecteur.
Dernière remarque, si on affiche dans la console un vecteur avec beaucoup d’éléments, ceux-ci seront répartis sur plusieurs lignes. Par exemple, si on a un vecteur de 50 nombres on peut obtenir quelque chose comme :
[1] 294 425 339 914 114 896 716 648 915 587 181 926 489
[14] 848 583 182 662 888 417 133 146 322 400 698 506 944
[27] 237 324 333 443 487 658 793 288 897 588 697 439 697
[40] 914 694 126 969 744 927 337 439 226 704 635On remarque que R ajoute systématiquement un nombre entre crochets au début de chaque ligne : il s’agit en fait de la position du premier élément de la ligne dans le vecteur. Ainsi, le 848 de la deuxième ligne est le 14e élément du vecteur, le 914 de la dernière ligne est le 40e, etc.
Ceci explique le [1] qu’on obtient quand on affiche un simple nombre2 :
[1] 4
On peut également effectuer une indexation multiple sur un vecteur si on souhaite sélectionner plusieurs élèments.
diplome[c(2,3,4)]## [1] "Bac" "Bac+2" "CAP"On peut également effectuer une indexation contraire sur un vecteur en précisant tous les élèments que l’on ne veut pas sélectionner. Pour cela, on utilise le ‘-’ devant l’indexation :
diplome[-2]## [1] "CAP" "Bac+2" "CAP" "Bac+3"diplome[- c(2,4)]## [1] "CAP" "Bac+2" "Bac+3"1.2.2.3 Type de vecteur
Les vecteurs peuvent être de classes différentes, selon le type de données qu’ils contiennent.
On a ainsi des vecteurs de type numeric, character ou logical:
numeric_vec <- c(10,55,49,4)
class(numeric_vec)## [1] "numeric"character_vec <- c("Jaune", "Vert", "Bleu", "Rouge")
class(character_vec)## [1] "character"logical_vec <- c(TRUE,FALSE,FALSE,TRUE)
class(logical_vec)## [1] "logical"Attention : dans un vecteur, tous les éléments sont de même type :
un_vecteur <- c("Luca", 30, 2000, FALSE)
class(un_vecteur)## [1] "character"un_vecteur## [1] "Luca" "30" "2000" "FALSE"Il existe des fonctions pour tester la classe d’un vecteur. Elles s’écrivent avec le même préfixe is.classe_a_tester. Ces fonctions sont des tests logiques donc elles renvoient toujours des booléens.
is.numeric(numeric_vec)## [1] TRUEis.numeric(character_vec)## [1] FALSEis.character(numeric_vec)## [1] FALSEis.character(character_vec)## [1] TRUEis.logical(logical_vec)## [1] TRUEis.logical(character_vec)## [1] FALSEIl est également possible de modifier la classe d’un vecteur avec les fonctions as.new_class.
as.character(numeric_vec)## [1] "10" "55" "49" "4"as.numeric(logical_vec)## [1] 1 0 0 1Dans R, les variables qualitatives peuvent être de deux types : ou bien des vecteurs de type character (des chaînes de caractères), ou bien des factor (facteurs).
En R, la classe factor est un vecteur contenant uniquement certaines valeurs prédéfinies. Ces valeurs pré-définies sont appelées des levels.
diplome <- c("CAP", "Bac", "Bac+2", "CAP", "Bac+3")
class(diplome)## [1] "character"diplome <- as.factor(diplome)
diplome## [1] CAP Bac Bac+2 CAP Bac+3
## Levels: Bac Bac+2 Bac+3 CAPclass(diplome)## [1] "factor"Si on souhaite modifier ou ajouter un élèment avec une modalité qui n’est pas pris en compte dans les levels, nous allons avoir une erreur.
diplome[6] <- "Master"## Warning in `[<-.factor`(`*tmp*`, 6, value = "Master"): niveau de facteur
## incorrect, NAs générésdiplome## [1] CAP Bac Bac+2 CAP Bac+3 <NA>
## Levels: Bac Bac+2 Bac+3 CAPIl faut donc modifier les levels acceptés par le vecteur en amont.
levels(diplome) <- c(levels(diplome), "Master")
diplome[6] <- "Master"
diplome## [1] CAP Bac Bac+2 CAP Bac+3 Master
## Levels: Bac Bac+2 Bac+3 CAP MasterMais à quoi peut servir tout cela ? En réalité, l’intérêt principal de la classe factor est de prendre moins de place en mémoire car les levels sont stockés en numeric. Si on transforme notre vecteur en classe numeric nous n’allons pas avoir d’erreur.
class(diplome)## [1] "factor"diplome <- as.numeric(diplome)
class(diplome)## [1] "numeric"diplome## [1] 4 1 2 4 3 5On observe que les nombres obtenus correspondent aux numéros de levels. Il faut donc faire trés attention lorsqu’on veut passer une classe numeric à une variable quantitative importée en tant que factor.
1.2.3 Fonctions
1.2.3.1 Principe
Nous savons désormais effectuer des opérations arithmétiques de base sur des nombres et des vecteurs, et stocker des valeurs dans des objets pour pouvoir les réutiliser plus tard.
Pour aller plus loin, nous devons aborder les fonctions qui sont, avec les objets, un deuxième concept de base de R. On utilise des fonctions pour effectuer des calculs, obtenir des résultats et accomplir des actions.
Formellement, une fonction a un nom, elle prend en entrée entre parenthèses un ou plusieurs arguments (ou paramètres), et retourne un résultat.
Prenons tout de suite un exemple. Si on veut connaître le nombre d’éléments du vecteur tailles que nous avons construit précédemment, on peut utiliser la fonction length, de cette manière :
length(tailles)## [1] 5Ici, length est le nom de la fonction, on l’appelle en lui passant un argument entre parenthèses (en l’occurrence notre vecteur tailles), et elle nous renvoie un résultat, à savoir le nombre d’éléments du vecteur passé en paramètre.
Autre exemple, les fonctions min et max retournent respectivement les valeurs minimales et maximales d’un vecteur de nombres :
min(tailles)## [1] 147max(tailles)## [1] 197La fonction mean calcule et retourne la moyenne d’un vecteur de nombres :
mean(tailles)## [1] 167.4La fonction sum retourne la somme de tous les éléments du vecteur :
sum(tailles)## [1] 837Jusqu’à présent on n’a vu que des fonctions qui calculent et retournent un unique nombre. Mais une fonction peut renvoyer d’autres types de résultats. Par exemple, la fonction range (étendue) renvoie un vecteur de deux nombres, le minimum et le maximum :
range(tailles)## [1] 147 197Ou encore, la fonction unique, qui supprime toutes les valeurs en double dans un vecteur, qu’il s’agisse de nombres ou de chaînes de caractères :
diplome <- c("CAP", "Bac", "Bac+2", "CAP", "Bac+3")
unique(diplome)## [1] "CAP" "Bac" "Bac+2" "Bac+3"1.2.3.2 Arguments
Une fonction peut prendre plusieurs arguments, dans ce cas on les indique toujours entre parenthèses, séparés par des virgules.
On a déjà rencontré un exemple de fonction acceptant plusieurs arguments : la fonction c, qui combine l’ensemble de ses arguments en un vecteur3 :
tailles <- c(156, 164, 197, 181, 173)Ici, c est appelée en lui passant cinq arguments, les cinq tailles séparées par des virgules, et elle renvoie un vecteur numérique regroupant ces cinq valeurs.
Supposons maintenant que dans notre vecteur tailles nous avons une valeur manquante (une personne a refusé de répondre). On symbolise celle-ci dans R avec le code interne NA :
tailles <- c(156, 164, 197, NA, 173)
tailles## [1] 156 164 197 NA 173NA est l’abréviation de Not available, non disponible. Cette valeur particulière peut être utilisée pour indiquer une valeur manquante, qu’il s’agisse d’un nombre, d’une chaîne de caractères, etc.
Si je calcule maintenant la taille moyenne à l’aide de la fonction mean, j’obtiens :
mean(tailles)## [1] NAEn effet, R considère par défaut qu’il ne peut pas calculer la moyenne si une des valeurs n’est pas disponible. Il considère alors que cette moyenne est elle-même “non disponible” et renvoie donc comme résultat NA.
On peut cependant indiquer à mean d’effectuer le calcul en ignorant les valeurs manquantes. Ceci se fait en ajoutant un argument supplémentaire, nommé na.rm (abréviation de NA remove, “enlever les NA”), et de lui attribuer la valeur TRUE (code interne de R signifiant vrai) :
mean(tailles, na.rm = TRUE)## [1] 172.5Positionner le paramètre na.rm à TRUE indique à la fonction mean de ne pas tenir compte des valeurs manquantes dans le calcul.
Si on ne dit rien à la fonction mean, cet argument a une valeur par défaut, en l’occurrence FALSE (faux), qui fait qu’il ne supprime pas les valeurs manquantes. Les deux commandes suivantes sont donc rigoureusement équivalentes :
mean(tailles)## [1] NAmean(tailles, na.rm = FALSE)## [1] NALorsqu’on passe un argument à une fonction de cette manière, c’est-à-dire sous la forme nom = valeur, on parle d’argument nommé.
1.2.3.3 Aide sur une fonction
Il est fréquent de ne pas savoir (ou d’avoir oublié) quels sont les arguments d’une fonction, ou comment ils se nomment. On peut à tout moment faire appel à l’aide intégrée à R en passant le nom de la fonction (entre guillemets) à la fonction help :
help("mean")?meanOn peut aussi utiliser le raccourci ?mean.
Ces deux commandes affichent une page (en anglais) décrivant la fonction, ses paramètres, son résultat, le tout accompagné de diverses notes, références et exemples. Ces pages d’aide contiennent à peu près tout ce que vous pourrez chercher à savoir, mais elles ne sont pas toujours d’une lecture aisée.
Dans RStudio, les pages d’aide en ligne s’ouvriront par défaut dans la zone en bas à droite, sous l’onglet Help. Un clic sur l’icône en forme de maison vous affichera la page d’accueil de l’aide.
1.2.3.4 Programmer des fonctions
Il est possible de programmer ses propres fonctions. Dans l’exemple ci-dessous on construit une fonction imcq ui prend en entrée deux arguments poids et taille. La fonction effectue un calcul et renvoi l’IMC. Pour construire une fonction, on doit obligatoirement faire appel au mot clé function. Le mot clé return n’est pas obligatoire. Cependant, par convention, une fonction renvoie toujours un résultat qui peut aussi être un message d’information sur le bon déroulement de celle-ci. Les arguments sont précisés entre parenthèses ( ). Les traitements s’effectuent entre accolades { }.
imc <- function(taille,poids) {
calcul <- poids / (taille^2)
return (calcul) }Lorsqu’on vérifie la classe de l’objet imc en mémoire, on constate qu’il est bien de type function.
class(imc)## [1] "function"Puis c’est le même principe que les autres fonctions pour l’utiliser :
imc(taille = 1.55, poids = 49)## [1] 20.39542Il est possible de préciser des arguments par défaut. Ils sont à saisir dans la définition des arguments :
imc <- function(taille = 1.70, poids = 60) {
calcul <- poids / (taille^2)
return (calcul) }
imc()## [1] 20.761251.3 Fonctions de tests et comparaisons
Dans R, il est possible d’effectuer des comparaisons ou des tests qui vont retourner la valeur TRUE si vrai et FALSE si faux
1.3.1 Opérateurs de comparaisons
Voici les différents opérateurs de comparaisons que l’on peut utiliser :

Opérateurs de comparaison
a <- c(1,3,5,9)
b <- c(1,2,6,9)a > b## [1] FALSE TRUE FALSE FALSEa == b## [1] TRUE FALSE FALSE TRUEa != b## [1] FALSE TRUE TRUE FALSE1.3.2 Opérateurs logiques
Ces opérateurs permettent de tester l’effet de plusieurs tests logiques.
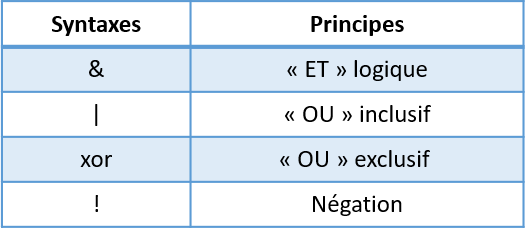
Opérateurs logiques
a <- c(1,3,5,9)
b <- c(1,2,6,9)(a > b) & ( a > 4)## [1] FALSE FALSE FALSE FALSE(a == b) | (a > 4)## [1] TRUE FALSE TRUE TRUExor(a > b, a > 4)## [1] FALSE TRUE TRUE TRUEa > b## [1] FALSE TRUE FALSE FALSE! a > b## [1] TRUE FALSE TRUE TRUE1.3.3 Fonctions logiques
Il existe des fonctions pour effectuer des tests logiques. Elles ont toutes le même préfixe et s’écrivent is.mon_test. On peut par exemple tester la classe d’un objet avec les fonctions is.classe_a_tester. Ces fonctions sont des tests logiques donc elles renvoient toujours des booléens (rappel TD1).
numeric_vec <- c(10,55,49,4)
class(numeric_vec)## [1] "numeric"character_vec <- c("Jaune", "Vert", "Bleu", "Rouge")
class(character_vec)## [1] "character"is.numeric(numeric_vec)## [1] TRUEis.numeric(character_vec)## [1] FALSEis.character(numeric_vec)## [1] FALSEis.character(character_vec)## [1] TRUEOn peut aussi tester la présence FALSE/ TRUE de valeurs manquantes NA avec la fonction is.na.
a <- c(1,NA,6,9)
is.na(a)## [1] FALSE TRUE FALSE FALSE1.4 Regrouper ses commandes dans des scripts
Jusqu’ici on a utilisé R de manière “interactive”, en saisissant des commandes directement dans la console. Ça n’est cependant pas la manière dont on va utiliser R au quotidien, pour une raison simple : lorsque R redémarre, tout ce qui a été effectué dans la console est perdu.
Plutôt que de saisir nos commandes dans la console, on va donc les regrouper dans des scripts (de simples fichiers texte), qui vont garder une trace de toutes les opérations effectuées, et ce sont ces scripts, sauvegardés régulièrement, qui seront le “coeur” de notre travail. C’est en rouvrant les scripts et en réexécutant les commandes qu’ils contiennent qu’on pourra “reproduire” les données, leur traitement, les analyses et leurs résultats.
Pour créer un script, il suffit de sélectionner le menu File, puis New file et R script. Une quatrième zone apparaît alors en haut à gauche de l’interface de RStudio. On peut enregistrer notre script à tout moment dans un fichier avec l’extension .R, en cliquant sur l’icône de disquette ou en choisissant File puis Save.
Un script est un fichier texte brut, qui s’édite de la manière habituelle. À la différence de la console, quand on appuie sur Entrée, cela n’exécute pas la commande en cours mais insère un saut de ligne (comme on pouvait s’y attendre).
Pour exécuter une commande saisie dans un script, il suffit de positionner le curseur sur la ligne de la commande en question, et de cliquer sur le bouton Run dans la barre d’outils juste au-dessus de la zone d’édition du script. On peut aussi utiliser le raccourci clavier Ctrl + Entrée (Cmd + Entrée sous Mac). On peut enfin sélectionner plusieurs lignes avec la souris ou le clavier et cliquer sur Run (ou utiliser le raccourci clavier), et l’ensemble des lignes est exécuté d’un coup.
Finalement, un script pourra ressembler à quelque chose comme ça :
tailles <- c(156, 164, 197, 147, 173)
poids <- c(45, 59, 110, 44, 88)
mean(tailles)
mean(poids)
imc <- poids / (tailles / 100) ^ 2
min(imc)
max(imc)1.4.1 Commentaires
Les commentaires sont un élément très important d’un script. Il s’agit de texte libre, ignoré par R, et qui permet de décrire les étapes du script, sa logique, les raisons pour lesquelles on a procédé de telle ou telle manière… Il est primordial de documenter ses scripts à l’aide de commentaires, car il est très facile de ne plus se retrouver dans un programme qu’on a produit soi-même, même après une courte interruption.
Pour ajouter un commentaire, il suffit de le faire précéder d’un ou plusieurs symboles #. En effet, dès que R rencontre ce caractère, il ignore tout ce qui se trouve derrière, jusqu’à la fin de la ligne.
On peut donc documenter le script précédent :
# Saisie des tailles et poids des enquêtés
tailles <- c(156, 164, 197, 147, 173)
poids <- c(45, 59, 110, 44, 88)
# Calcul des tailles et poids moyens
mean(tailles)
mean(poids)
# Calcul de l'IMC (poids en kilo divisé par les tailles en mètre au carré)
imc <- poids / (tailles / 100) ^ 2
# Valeurs extrêmes de l'IMC
min(imc)
max(imc)1.5 Installer et charger des extensions (packages)
R étant un logiciel libre, il bénéficie d’un développement communautaire riche et dynamique. L’installation de base de R permet de faire énormément de choses, mais le langage dispose en plus d’un système d’extensions permettant d’ajouter facilement de nouvelles fonctionnalités. La plupart des extensions sont développées et maintenues par la communauté des utilisateurs de R, et diffusées via un réseau de serveurs nommé CRAN (Comprehensive R Archive Network).
Pour installer une extension, si on dispose d’une connexion Internet, on peut utiliser le bouton Install de l’onglet Packages de RStudio.
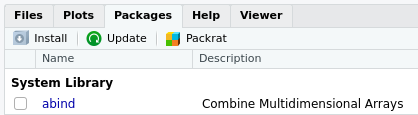
Installer une extension
Il suffit alors d’indiquer le nom de l’extension dans le champ Package et de cliquer sur Install.
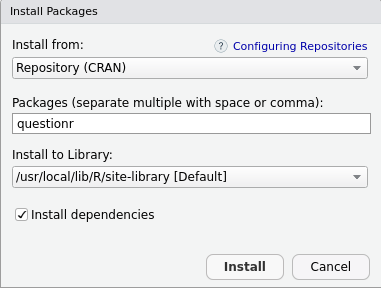
Installation d’une extension
On peut aussi installer des extensions en utilisant la fonction install.packages() directement dans la console. Par exemple, pour installer le package questionr on peut exécuter la commande :
install.packages("questionr")Installer une extension via l’une des deux méthodes précédentes va télécharger l’ensemble des fichiers nécessaires depuis l’une des machines du CRAN, puis installer tout ça sur le disque dur de votre ordinateur. Vous n’avez besoin de le faire qu’une fois, comme vous le faites pour installer un programme sur votre Mac ou PC. Cela suppose que vous disposez d’une connexion internet. Cependant, il est possible d’installer des packages en local sans connexion internet sous réserve d’être en possession des packages en fichiers zippés.
Une fois l’extension installée, il faut la “charger” avant de pouvoir utiliser les fonctions qu’elle propose. Ceci se fait avec la fonction library. Par exemple, pour pouvoir utiliser les fonctions de questionr, vous devrez exécuter la commande suivante :
library(questionr)Ainsi, bien souvent, on regroupe en début de script toute une série d’appels à library qui permettent de charger tous les packages utilisés dans le script. Quelque chose comme :
library(readxl)
library(ggplot2)
library(questionr)Si vous essayez d’exécuter une fonction d’une extension et que vous obtenez le message d’erreur impossible de trouver la fonction, c’est certainement parce que vous n’avez pas exécuté la commande library correspondante.
1.6 Exercices
1.6.1 Sujet
Exercice 1
- Construire le vecteur
xsuivant :
## [1] 120 134 256 12- Utiliser ce vecteur
xpour générer les deux vecteurs suivants :
## [1] 220 234 356 112## [1] 240 268 512 24Exercice 2
On a demandé à 4 ménages le revenu des deux conjoints, et le nombre de personnes du ménage :
conjoint1 <- c(1200, 1180, 1750, 2100)
conjoint2 <- c(1450, 1870, 1690, 0)
nb_personnes <- c(4, 2, 3, 2)Calculer le revenu total de chaque ménage, puis diviser par le nombre de personnes pour obtenir le revenu par personne de chaque ménage.
Exercice 3
- Dans l’exercice précédent, calculer le revenu minimum et maximum parmi ceux du premier conjoint.
conjoint1 <- c(1200, 1180, 1750, 2100)- Recommencer avec les revenus suivants, parmi lesquels l’un des enquêtés n’a pas voulu répondre :
conjoint1 <- c(1200, 1180, 1750, NA)Exercice 4
Les deux vecteurs suivants représentent les précipitations (en mm) et la température (en °C) moyennes sur la ville de Lyon, pour chaque mois de l’année, entre 1981 et 2010 :
temperature <- c(3.4, 4.8, 8.4, 11.4, 15.8, 19.4, 22.2, 21.6, 17.6, 13.4, 7.6, 4.4)
precipitations <- c(47.2, 44.1, 50.4, 74.9, 90.8, 75.6, 63.7, 62, 87.5, 98.6, 81.9, 55.2)Calculer la température moyenne sur l’année.
Calculer la quantité totale de précipitations sur l’année.
À quoi correspond et comment peut-on interpréter le résultat de la fonction suivante ? Vous pouvez vous aider de la page d’aide de la fonction si nécessaire.
cumsum(precipitations)## [1] 47.2 91.3 141.7 216.6 307.4 383.0 446.7 508.7 596.2 694.8 776.7 831.9- Même question pour :
diff(temperature)## [1] 1.4 3.6 3.0 4.4 3.6 2.8 -0.6 -4.0 -4.2 -5.8 -3.2Exercice 5
On a relevé les notes en maths, anglais et sport d’une classe de 6 élèves et on a stocké ces données dans trois vecteurs :
maths <- c(12, 16, 8, 18, 6, 10)
anglais <- c(14, 9, 13, 15, 17, 11)
sport <- c(18, 11, 14, 10, 8, 12)Calculer la moyenne des élèves de la classe en anglais.
Calculer la moyenne générale de chaque élève.
Essayez de comprendre le résultat des deux fonctions suivantes (vous pouvez vous aider de la page d’aide de ces fonctions) :
pmin(maths, anglais, sport)## [1] 12 9 8 10 6 10pmax(maths, anglais, sport)## [1] 18 16 14 18 17 121.6.2 Correction
Exercice 1
- Construire le vecteur
xsuivant :
## [1] 120 134 256 12x <- c(120, 134, 256, 12)- Utiliser ce vecteur
xpour générer les deux vecteurs suivants :
## [1] 220 234 356 112## [1] 240 268 512 24x + 100
x * 2Exercice 2
On a demandé à 4 ménages le revenu des deux conjoints, et le nombre de personnes du ménage :
conjoint1 <- c(1200, 1180, 1750, 2100)
conjoint2 <- c(1450, 1870, 1690, 0)
nb_personnes <- c(4, 2, 3, 2)Calculer le revenu total de chaque ménage, puis diviser par le nombre de personnes pour obtenir le revenu par personne de chaque ménage.
revenu_total <- conjoint1 + conjoint2
revenu_total / nb_personnesExercice 3
- Dans l’exercice précédent, calculer le revenu minimum et maximum parmi ceux du premier conjoint.
conjoint1 <- c(1200, 1180, 1750, 2100)range(conjoint1)- Recommencer avec les revenus suivants, parmi lesquels l’un des enquêtés n’a pas voulu répondre :
conjoint1 <- c(1200, 1180, 1750, NA)range(conjoint1, na.rm = TRUE)Exercice 4
Les deux vecteurs suivants représentent les précipitations (en mm) et la température (en °C) moyennes sur la ville de Lyon, pour chaque mois de l’année, entre 1981 et 2010 :
temperature <- c(3.4, 4.8, 8.4, 11.4, 15.8, 19.4, 22.2, 21.6, 17.6, 13.4, 7.6, 4.4)
precipitations <- c(47.2, 44.1, 50.4, 74.9, 90.8, 75.6, 63.7, 62, 87.5, 98.6, 81.9, 55.2)- Calculer la température moyenne sur l’année.
mean(temperature)- Calculer la quantité totale de précipitations sur l’année.
sum(precipitations)- À quoi correspond et comment peut-on interpréter le résultat de la fonction suivante ? Vous pouvez vous aider de la page d’aide de la fonction si nécessaire.
cumsum(precipitations)## [1] 47.2 91.3 141.7 216.6 307.4 383.0 446.7 508.7 596.2 694.8 776.7 831.9- Même question pour :
diff(temperature)## [1] 1.4 3.6 3.0 4.4 3.6 2.8 -0.6 -4.0 -4.2 -5.8 -3.2cumsum(precipitations) correspond à la somme cumulée des précipitations sur l’année. Par exemple, la 6e valeur du vecteur résultat correspond au total de précipitations de janvier à juin.
diff(temperature) correspond à la différence de température d’un mois sur l’autre. Par exemple, la 2e valeur de ce vecteur correspond à l’écart de température entre le mois de février et le mois de janvier.
Exercice 5
On a relevé les notes en maths, anglais et sport d’une classe de 6 élèves et on a stocké ces données dans trois vecteurs :
maths <- c(12, 16, 8, 18, 6, 10)
anglais <- c(14, 9, 13, 15, 17, 11)
sport <- c(18, 11, 14, 10, 8, 12)- Calculer la moyenne des élèves de la classe en anglais.
mean(anglais)- Calculer la moyenne générale de chaque élève.
(maths + anglais + sport) / 3- Essayez de comprendre le résultat des deux fonctions suivantes (vous pouvez vous aider de la page d’aide de ces fonctions) :
pmin(maths, anglais, sport)## [1] 12 9 8 10 6 10pmax(maths, anglais, sport)## [1] 18 16 14 18 17 12pmin et pmax renvoient les minimum et maximum “parallèles” des trois vecteurs passés en argument. Ainsi, pmin renvoie pour chaque élève la note minimale dans les trois matières, et pmax la note maximale.
1.7 Testez vos connaissances !

Quiz
Testez vos connaissances sur ce chapitre avec ce quiz (10 min) en cliquant ici.